
El Atlas de hablas locales del euskera (‘Euskararen Herri Hizkeren Atlasa‘, EHHA) es una fuente de extraordinario valor para la dialectología vasca, la historia de la lengua, o la lingüística vascorrománica. Hasta la fecha se han publicado siete tomos, el último de ellos presentado recientemente por el director académico del proyecto Adolfo Arejita. El EHHA se suma a la lista de recursos que Euskaltzaindia comparte en internet. Entre ellos destacan el Diccionario general de euskera (‘Orotariko Euskal Hiztegia‘, OEH) y los 27 volúmenes del Onomasticon Vasconiae (descargables en PDF). De igual manera son especialmente valiosas para nuestros fines las Obras completas de Koldo Mitxelena (2011), publicadas por la UPV/EHU (con un práctico sistema de consulta multifuncional), el Fondo Bonaparte, del equipo TesiTek que dirige Rosa Miren Pagola en la Universidad de Deusto, así como los buscadores de datos toponímicos de los gobiernos de la CAV y de Navarra. Es especialmente loable la iniciativa del Gobierno Vasco de facilitar la descarga (datos abiertos en WMS, CSV, o MDB) de una buena parte del material toponímico.
Tal abundancia de recursos facilita sobremanera el trabajo, pero abruma en igual proporción. Con el fin de agilizar la consulta, ofrecemos en esta entrada un rápido muestreo de los siete tomos del atlas EHHA publicados hasta la fecha y cuyo contenido resumimos:
- Tomo 1: los insectos, los peces marinos, los peces fluviales y los aparejos de pesca, los reptiles, los animales subterráneos, las aves, los animales salvajes y artes cinegéticas, el sol y el firmamento, el tiempo atmosférico, la nieve y el frío
- Tomo 2: el tiempo atmosférico, el día, las festividades anuales, el relieve, los ríos, el campo, los vallados, los caminos, los árboles
- Tomo 3: los arbustos, las hortalizas, las plantas salvajes, la patata, la vaca, la yegua, las ovejas
- Tomo 4: el cerdo, las aves, el perro, la abeja, el caserío, la casa, el tejado, el maderaje, las partes de la casa, los muebles
- Tomo 5: la desinencia nominal; los numerales
- Tomo 6: los verbos auxiliares izan, *edin, *edun y ezan; las formas sintéticas; las formas alocutivas
- Tomo 7: la cocina, la yunta, el transporte, el arado, la labranza; los determinantes; asepctos de sintaxis
(Los enlaces llevan a nuestras tablas anotadas que a su vez remiten a los mapas de Euskaltzaindia.) La colección completa del EHHA (12 volúmenes) abarcará 85 temas, la mayoría relacionados con el mundo rural, distribuidos de la siguiente manera:
- Animales (01-06)
- El tiempo y otros aspectos celestes (07-13)
- Tierra y mar (14-18)
- Árboles y plantas (19-23)
- Animales domésticos y agricultura (24-31)
- El caserío (32-36)
- La vida en el caserío, herramientas y producción (49-57)
- El cuerpo, enfermedades, vida en familia (58-74)
- Vida social y laboral (65-85)
Los siete tomos publicados suman un total de 1808 mapas que ilustran un número muy significativo de fenómenos concernientes al estudio del léxico común y de las divergencias dialectales del euskera. Como primera aproximación vamos a seguir la recomendación de nuestro colega Jon Ortiz de Urbina y empezar consultando los mapas de las palabras contempladas en la lista de Swadesh, o para ser más precisos de las 40 palabras de la lista de Swadesh más estables (marcadas con un asterisco en la tabla de abajo) según los resultados lexicométricos de Holman y otros (2008):
| 22 *louse (42.8) 12 *two (39.8) 75 *water (37.4) 39 *ear (37.2) 61 *die (36.3) 1 *I (35.9) 53 *liver (35.7) 40 *eye (35.4) 48 *hand (34.9) 58 *hear (33.8) 23 *tree (33.6) 19 *fish (33.4) 100 *name (32.4) 77 *stone (32.1) 43 *tooth (30.7) 51 *breasts (30.7) 2 *you (30.6) 85 *path (30.2) 31 *bone (30.1) 44 *tongue (30.1) |
28 *skin (29.6) 92 *night (29.6) 25 *leaf (29.4) 76 rain (29.3) 62 kill (29.2) 30 *blood (29.0) 34 *horn (28.8) 18 *person (28.7) 47 *knee (28.0) 11 *one (27.4) 41 *nose (27.3) 95 *full (26.9) 66 *come (26.8) 74 *star (26.6) 86 *mountain (26.2) 82 *fire (25.7) 3 *we (25.4) 54 *drink (25.0) 57 *see (24.7) 27 bark (24.5) |
96 *new (24.3) 21 *dog (24.2) 72 *sun (24.2) 64 fly (24.1) 32 grease (23.4) 73 moon (23.4) 70 give (23.3) 52 heart (23.2) 36 feather (23.1) 90 white (22.7) 89 yellow (22.5) 20 bird (21.8) 38 head (21.7) 79 earth (21.7) 46 foot (21.6) 91 black (21.6) 42 mouth (21.5) 88 green (21.1) 60 sleep (21.0) 7 what (20.7) |
26 root (20.5) 45 claw (20.5) 56 bite (20.5) 83 ash (20.3) 87 red (20.2) 55 eat (20.0) 33 egg (19.8) 6 who (19.0) 99 dry (18.9) 37 hair (18.6) 81 smoke (18.5) 8 not (18.3) 4 this (18.2) 24 seed (18.2) 16 woman (17.9) 98 round (17.9) 14 long (17.4) 69 stand (17.1) 97 good (16.9) 17 man (16.7) |
94 cold (16.6) 29 flesh (16.4) 50 neck (16.0) 71 say (16.0) 84 burn (15.5) 35 tail (14.9) 78 sand (14.9) 5 that (14.7) 65 walk (14.4) 68 sit (14.3) 10 many (14.2) 9 all (14.1) 59 know (14.1) 80 cloud (13.9) 63 swim (13.6) 49 belly (13.5) 13 big (13.4) 93 hot (11.6) 67 lie (11.2) 15 small (6.3) |
El índice de estabilidad relativa de las palabras calculado por Holman y otros (2008) se indica entre paréntesis (de forma que louse ‘piojo’ se señala por ejemplo como la palabra con mayor índice de estabilidad, 42,8; seguida del numeral ‘dos’, 39,8, y del sustantivo ‘agua’, 37,4). Esta clasificación difiere del orden con el que intuitivamente Morris Swadesh había elaborado su lista, aunque coincide en una alta proporción con su selección de términos. La estabilidad atribuida a las palabras con asterisco debería plasmarse en nuestro caso en una mayor resistencia al cambio dialectal y por ende en una mayor perdurabilidad de las formas antiguas. Vemos que efectivamente la predicción se cumple en la mayoría de los casos (con la notable excepción de ‘ladrar’ bark):
| 22 | *louse | piojo | (mapa 31) | 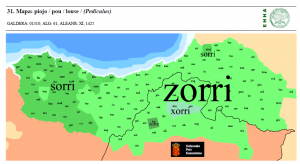 |
| 12 | *two | dos | (mapa 1233) | 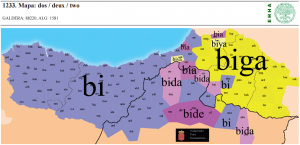 |
| 75 | *water | agua | (mapa 392) | 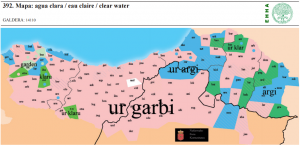 |
| 1 | *I | yo (pron.) | (mapa 1696) | 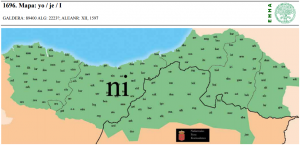 |
| 53 | *liver | hígado | (mapa 879) | 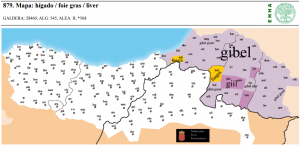 |
| 23 | *tree | árbol | (mapa 446) | 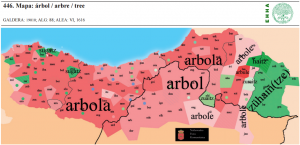 |
| 77 | *stone | piedra | (mapa 376) | 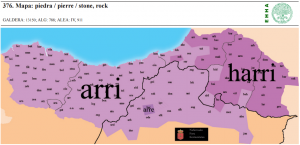 |
| 02 | *you | tú (pron.) | (mapa 1698) | 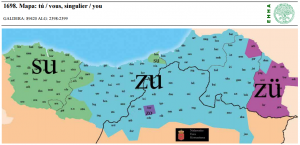 |
| 51 | *breasts | pecho (del caballo) | (mapa 708) | 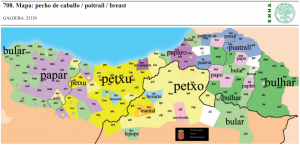 |
| 85 | *path | camino | (mapa 426) | 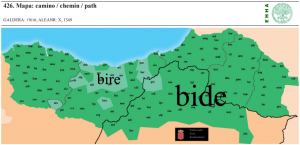 |
| 31 | *bone | hueso de la cadera, hipbone | (mapa 803) | 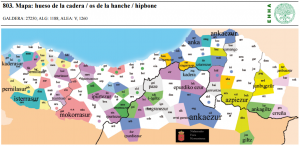 |
| 28 | *skin | piel de cerdo, leather | (mapa 806) | 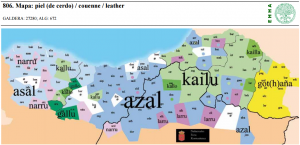 |
| 92 | *night | noche | (mapa 315) | 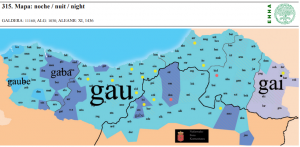 |
| 25 | *leaf | hoja | (mapa 450) | 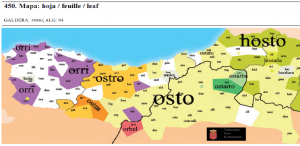 |
| 76 | rain | lluvia | (mapa 235) | 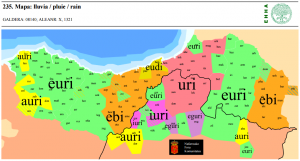 |
| 34 | *horn | cuerno | (mapa 626) | 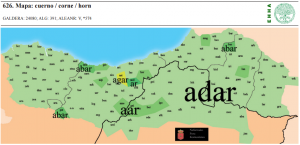 |
| 11 | *one | uno | (mapa 1232) | 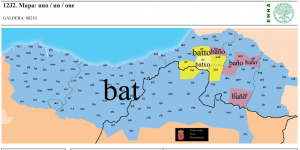 |
| 74 | *star | estrella | (mapa 208) | 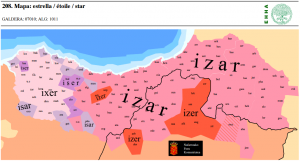 |
| 86 | *mountain | montaña | (mapa 363) | 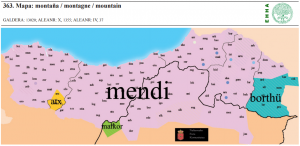 |
| 82 | *fire | fuego | (mapa 1015) | 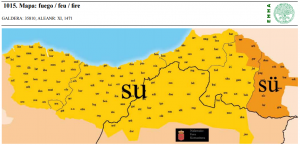 |
| 27 | bark | ladrar | (mapa 890) | 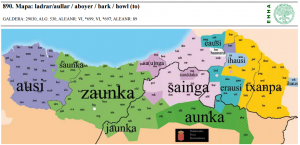 |
| 21 | *dog | perro | (mapa 888) | 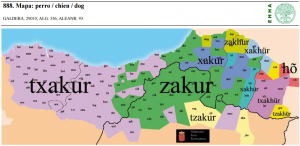 |
| 72 | *sun | sol | (mapa 217) | 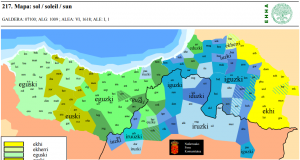 |
Los mapas confirman la previsión de que la perdurabilidad de las formas antiguas se corresponde con un factor de estabilidad más alto, conforme a la estimación introducida por Holman y otros (2008) en la lista reducida de Swadesh. Efectivamente, en la mayoría de los mapas consultados se observa una forma general, supuestamente antigua, con pequeñas variantes modernas:
- 22 *louse (42.8) piojo (mapa 31) zorri (con variante occidental z > s)
- 12 *two (39.8) dos (mapa 1233) bi (con variante oriental biga, posiblemente más antigua)
- 75 *water (37.4) agua (mapa 392) ur (el mapa recoge testimonios para ‘agua clara’)
- 01 *I (35.9) yo (mapa 1996) ni general
- 53 *liver (35.7) hígado (mapa 879) gibel (el mapa recoge las respuestas para foie gras)
- 40 23 *tree (33.6) árbol (mapa 446) el mapa ofrece dos variantes, la más general corresponde al préstamo latino arbola y la minoritaria, aparentemente patrimonial, a su vez exhibe dos subvariantes, una oriental zühain(tze) y otra occidental sugatz (con z > s)
- 77 *stone (32.1) piedra (mapa 376) harri (con pérdida de h en zona española)
- 51 *breasts (30.7) pechos (mapa 708) bular (el mapa muestra la variedad de respuestas para ‘pecho de caballo’)
- 02 *you (30.6) (mapa 1698) zu
- 85 *path (30.2) (mapa 426) bide (forma local guipuzcoana bire con d > r)
- 31 *bone (30.1) (mapa 803) ezur (las variantes responden a la respuesta para ‘hueso de la cadera’)
- 28 *skin (29.6) leather (mapa 806) azal (las variantes responden a la respuesta para ‘piel de cerdo’)
- 92 *night (29.6) noche (mapa 315) gau (variante oriental gai)
- 25 *leaf (29.4) hoja (mapa 450) hosto (variantes occidentales ostro y orri)
- 76 *rain (29.3) lluvia (mapa 235) euri (variantes en auri, ebi, uri)
- 34 *horn (28.8 cuerno (mapa 626) adar
- 74 *star (26.6) estrella (mapa 208) izar (variantes occidentales isar, ixer)
- 86 *mountain (26.2) montaña (mapa 363) mendi (variante oriental borthü)
- 82 *fire (25.7) fuego (mapa 1015) su (variante oriental sü)
- 27 bark (24.5) ladrar (mapa 890) palabra que no ha sido marcada con * y que no exhibe estabilidad, como se desprende de la elevada variedad de formas registradas: ausi, zaunka, aunka, sainka, erausi, ihausi, txanpa. Llama la atención que en la zona occidental se mantenga una aparente forma antigua derivada de < hausi, con variantes causativas en zona oriental erausi, ihausi; en la zona central se recoge una alternativa léxica con apariencia onomatopéyica zaunka. La variante más oriental txanpa podría tratarse de una forma asimismo onomatopéyica y posiblemente más reciente (ver OEH)
- 21 *dog (24.2) perro (mapa 888) zakur es la forma más antigua y general; las variantes responden a palatalizaciones de la sibilante inicial
- 72 *sun (24.2) sol (mapa 217) eguzki, con variantes menores eduzki, eruzki (g > d/r) y oriental más significativa ekhi.
Quedan por revisar los otros términos marcados con asterisco que todavía no se han publicado en EHHA y que suponemos en un porcentaje muy elevando mantendrán la estabilidad observada en los mapas reproducidos arriba:
- 39 *ear (37.2) oreja
- 61 *die (36.3) morir
- 53 *liver (35.7) hígado
- 40 *eye (35.4) ojo
- 48 *hand (34.9) mano
- 58 *hear (33.8) oír
- 19 *fish (33.4) pez
- 100 *name (32.4) nombre
- 43 *tooth (30.7) diente
- 51 *breasts (30.7) pechos
- 44 *tongue (30.1) lengua
- 28 *skin (29.6) piel
- 62 *kill (29.2) matar
- 30 *blood (29.0) sangre
- 18 *person (28.7) persona
- 47 *knee (28.0) rodilla
- 11 *one (27.4) uno
- 41 *nose (27.3) nariz
- 95 *full (26.9) lleno
- 66 *come (26.8) venir
- 74 3 *we (25.4) nosotros
- 54 *drink (25.0) beber
- 57 *see (24.7) ver
- 96 *new (24.3) nuevo
Listados como el de Swadesh han ido ganando popularidad entre los estudiosos de la glotocronología, la lingüística comparada, o la filogenia aplicada a la lngüística histórica. Cabe destacar, por su considerable eco mediático, el trabajo Ultraconserved words point to deep language ancestry across Eurasia de Pagel y otros (2013), del que existen dos reseñas muy severas cuya lectura es imprescindible, una de Sally Thomason (Ultraconserved words? Really??) y otra de Asya Pereltsvaig (Ultraconserved words reveal linguistic macro-families?).
Para finalizar queremos mencionar el proyecto World Loanword Database (WLD) de Haspelmath, Martin y Tadmor, Uri 2009, que ofrece listados de palabras alternativos al de Swadesh en un amplio abanico de lenguas y cuya disponibilidad facilita experimentos muy ambiciosos como el reciente Inferring the world tree of languages from word lists de Jaeger G. y Wichmann S. (2016).
Referencias
- Haspelmath, M., & Tadmor, U. (2009). Loanwords in the world’s languages: a comparative handbook. Walter de Gruyter.
- Holman, E. W., Wichmann, S., Brown, C. H., Velupillai, V., Müller, A., & Bakker, D. (2008). Explorations in automated language classification. Folia Linguistica, 42(3-4), 331-354. Dsiponible en red: http://www.degruyter.com/view/j/flin.2008.42.issue-2/flin.2008.331/flin.2008.331.xml
- Jaeger G. and Wichmann S. (2016). Inferring The World Tree Of Languages From Word Lists. In S.G. Roberts, C. Cuskley, L. McCrohon, L. Barceló-Coblijn, O. Fehér & T. Verhoef (eds.) The Evolution of Language: Proceedings of the 11th International Conference (EVOLANG11). Disponible en red: http://evolang.org/neworleans/papers/147.html
- Pagel, M., Atkinson, Q. D., Calude, A. S., & Meade, A. (2013). Ultraconserved words point to deep language ancestry across Eurasia. Proceedings of the National Academy of Sciences, 110 (21), 8471-8476. Disponible en red: http://www.pnas.org/content/110/21/8471.full.
2 respuestas a «Los términos de la lista Swadesh en el EHHA»
En mi opinión, tanto la «glotocronología» como la llamada «lexicostatistics» basadas en listas como la de Swadesh son intentos fallidos de aplicar un modelo matemático a una realidad (las lenguas) que no se comporta de esa manera.
Gracias de nuevo Octavià por tus comentarios. Estoy contigo en tu escepticismo hacia los métodos estadísticos, pero con algún matiz. Creo que estos métodos pueden alertarnos de tendencias, de patrones de proximidad, de concurrencias entre cognados y préstamos que de otra forma tal vez pasarían desapercibidos (me refiero a lo que pueda llegar a dar un proyecto como el World Loanword Database (WLD)). Son métodos de «vista de pájaro», que con frecuencia fallan en el detalle, como muy bien han puesto de manifiesto Sally Thomason y Asya Pereltsvaig en su crítica del uso de «palabras ultraconservadoras» de Pagel y otros (2013).
Del atlas EHHA se han publicado ya cerca de 2000 mapas muchos de los cuales me parecen fascinantes. Es la recurrencia de algunos patrones la que puede resultar significativa, como sucede con la toponimia, no los casos excepcionales o anómalos, aunque muchas veces estos también esconden fenómenos relevantes.
Me he apresurado a publicar esta entrada porque tenía prisa por compartir las hojas de cálculo anotadas y enlazadas a los mapas, mucho más prácticas que el sistema de consulta de Euskaltzaindia. Además se pueden dejar comentarios, si alguien encuentra un buen motivo para hacerlo. Están en dos formatos: para consulta rápida, o para consulta comentada.
Tengo otra entrada a medio cocinar en la que explico los códigos con los que anoto los mapas. Por supuesto, está todo en fase de elaboración.